
Beyond Final Answers: Information-Architecture Blindness in LLM Belief Updating
Published in conference, 2026
M. Emre Bilgin
Read the paper
- Paper: arXiv link coming soon
- Code and data: GitHub link coming soon
- Figures and benchmark materials: Project page coming soon
If you are interested in LLM evaluation, Bayesian reasoning, cognitive science, or process-level supervision, I would be happy to discuss.
Introduction
Most LLM benchmarks ask a simple question: did the model get the final answer right?
But in uncertain reasoning, the final answer is not the whole story.
Imagine a model sees evidence in two steps. If the first cue is informative, its belief should move immediately. If the first cue is useless and only the relation between two cues matters, the model should wait. A correct final answer is not enough; the model should update for the right evidence, at the right time.
In our new paper, we test exactly this.

Our benchmark evaluates belief trajectories, not just final choices. The task compares model updates against both Bayesian posterior targets and human participant trajectories.
The problem: final answers can hide broken belief updates
Reasoning under uncertainty is sequential. Evidence arrives over time, and a good reasoner should revise its beliefs as new information becomes available.
This means that evaluation should not only ask whether a model eventually chooses the correct answer. It should also ask:
- Did the model update when evidence became informative?
- Did it update in the right direction?
- Did it distinguish evidence carried by individual cues from evidence carried by relations between cues?
A model can get the final answer right through a shortcut, a response prior, or a lucky heuristic. But if its intermediate beliefs do not track the structure of evidence, then something important is missing.
What we tested
We introduce a human-grounded, Bayesian-referenced benchmark for stage-wise belief updating.
On each trial, an agent must infer whether a hidden state is System A or System B. The agent observes one cue, reports a probability, observes a second cue, reports an updated probability, and then makes a final binary choice.
The key manipulation is the structure of evidence.
| Evidence structure | What carries information? | What should happen? |
|---|---|---|
| Redundancy-dominant | Individual cues | Beliefs should update early, after Cue 1 |
| Synergy-dominant | Relation between cues | Beliefs should wait, then update after Cue 2 |
In redundancy-dominant trials, each cue is separately diagnostic. A single cue should already shift the posterior.
In synergy-dominant trials, individual cue values are uninformative. Diagnostic evidence appears only after the relation between the two cues becomes available.
This lets us test whether models track not only the amount of evidence, but also where the evidence is carried.
What we found
Human participants were not perfectly Bayesian. That is expected.
But their errors were structured. They updated early when individual cues were informative, and they updated later when information became available only through cue relations.
Most evaluated LLMs showed much weaker sensitivity to this diagnostic structure. Some models achieved non-trivial final-choice accuracy or looked reasonable under aggregate metrics, but their posterior trajectories often failed to reflect when and where the evidence actually became informative.
We call this failure mode information-architecture blindness.
Information-architecture blindness is weak sensitivity, at the belief-trajectory level, to whether evidence is carried by individual observations or by relations between observations.
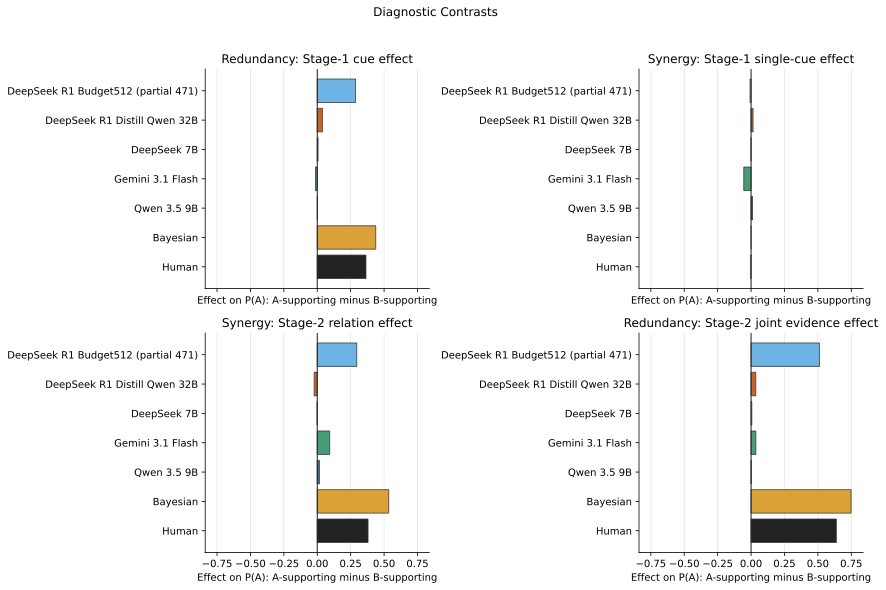
Diagnostic contrasts reveal whether belief reports separate at the theoretically correct stage for each information architecture. Humans and the Bayesian reference show clear structure; many LLMs show much weaker architecture sensitivity.
Why this matters
This matters because final-answer accuracy can miss process-level failures.
A model may choose the right final answer while updating too early, too late, in the wrong direction, or for the wrong evidence. For uncertainty-aware reasoning, we need to evaluate belief trajectories, not only final outputs.
This is especially important for future systems that aim to reason over sequential evidence, maintain uncertainty, use process supervision, or explicitly track intermediate belief states.
Our benchmark provides a simple behavioral target:
A model should update at the stage where diagnostic information becomes available, and its posterior trajectory should reflect whether that information is individual or relational.
What comes next
This study uses a controlled text-only replay protocol. That gives us clean Bayesian targets and a fair comparison to human participant data.
A natural next step is to extend the same benchmark to vision-language models, using the original human experimental interface. This would test whether models can both perceive the visual cue display and update beliefs according to the same information architecture.
More broadly, we want to understand when LLMs merely produce plausible answers, and when they actually track the structure of evidence over time.
Cite
Bilgin, D. (2024). "Beyond Final Answers: Information-Architecture Blindness in LLM Belief Updating" ``conference ``.